简介
Core Data 是 Apple 为 iOS,macOS,watchOS 和 tvOS 设计的对象图管理 (object graph management) 和数据持久化框架。如果你的 app 需要存储结构化的数据,Core Data 是一个显而易见的方案:它是现成的,Apple 仍然在积极地维护它,而且它已经存在超过 10 年了。Core Data 是一个成熟,经过实践检验的代码库。
然而 Core Data 刚开始会让人有些困惑:它非常灵活,但是 API 的最佳实践却并非显而易见。换句话说,本书的目标是帮助你快速入门 Core Data。我们希望提供给你一系列包括从简单到高级的使用场景中的最佳实践,这样你可以充分利用 Core Data 的能力而又不会迷失在一些不必要的复杂性中。
比如说,Core Data 经常被诟病难以在多线程环境中使用。其实 Core Data 的并发模型非常地明确和一致。如果正确使用,它可以帮助你避免许多并发编程中一些固有的陷阱。其他的复杂性并不是由 Core Data 引入的,它们的根源其实是并发本身。我们将在多上下文可能出现的问题一章中将对其进行深入研究,在另外一章我们还会实际演示一个后台同步方案的例子。
除此之外,Core Data 也经常被吐槽性能糟糕。如果你像使用关系型数据库那样来使用 Core Data,你会发现与直接使用像是 SQLite 这样的数据库相比,Core Data 的性能开销会很高。但如果把 Core Data 当成一个对象图管理系统来正确使用的时候,得益于内建的缓存和对象管理机制,它在很多方面实际上反而更快。此外,抽象级别更高的 API 可以让你专注于优化 app 里关键部分的性能,而不是从头开始来实现如何持久化。本书中,我们会介绍保持 Core Data 高性能的最佳实践。我们将在专门讲性能以及性能分析的章节中探讨如何解决 Core Data 的性能问题。
本书使用 Core Data 的方式
本书展示了如何在实际例子中使用 Core Data,而不仅仅是简单地对 API 手册进行一些扩展。我们有意专注于完整例子的最佳实践。根据我们的经验,正确地组合使用 Core Data 的各个部分往往是最大的挑战。
此外,本书还深入解释了 Core Data 内部的运作原理。了解 Core Data 这个灵活框架可以帮助你做出正确的决定,同时能让你的代码保持简单易懂。特别是当遇到并发和性能问题时,这一点尤为重要。
示例代码
你可以在 GitHub 上找到一个完整的示例程序的源代码。我们在本书中很多地方都将用这个示例程序来演示 Core Data 在较大的项目中面临的挑战和相应的解决方案。
我们已经将这个示例程序分成了几个不同的阶段,以便 GitHub 上的代码能和本书中的代码片段尽可能得对应上。
结构
在本书的第一部分,我们将开始创建一个简单版本的应用程序,来演示如何使用 Core Data 以及 Core Data 的基本工作原理。即使早期的示例对你来说可能相当容易,但我们仍然建议你浏览本书的这些部分,因为后面更复杂的例子是建立在前面介绍的最佳实践和技术基础之上的。我们还想告诉你的是,即便在简单的应用场景中,Core Data 也会非常有用。
第二部分则着重深入了解 Core Data 各个部分是如何一起协作的。我们将仔细探讨当以不同方式访问数据时会发生什么,我们也会对插入或者操作数据时发生的情况进行研究。这部分所覆盖的内容会比写一个简单的 Core Data 应用程序所必要的多得多,这些方面的知识在处理更大或更复杂的情况时可以派上用场。在此基础上,我们将以性能方面的考量来对这个部分进行总结。
第三部分从描述一个用来保持本地数据与网络服务一致的通用同步架构开始,然后我们将深入探讨如何在 Core Data 中同时使用多个托管对象上下文 (managed object context)。我们提出设置 Core Data 栈的不同方案,并讨论了它们的优缺点。在这部分的最后一章里,介绍了如何应对同时使用多个上下文带来的额外复杂性。
第四部分涉及一些高级的主题,比如:高级的谓词 (predicate),搜索和文本排序,如何在不同的数据模型版本之间迁移数据,以及分析 Core Data 栈的性能时所需要的工具和技术等。这部分中有一章是从 Core Data 视角介绍有关关系数据库和 SQL 查询语言的基本知识的。如果你不熟悉这些内容,这些章节能对你有所帮助,特别是可以让你理解 Core Data 潜在的性能问题,以及解决这些问题所需要的分析技术。
关于 Swift 的一些说明
贯穿本书,我们所有的示例都使用 Swift 编写。我们拥抱 Swift 的语言特性 — 比如泛型、协议以及扩展 — 它们能让我们更优雅、简单、安全地使用 Core Data 的 API。
用 Swift 表示的最佳实践和设计模式同样也适用于 Objective-C 的代码。实现上由于语言上的不同或许某些方面会稍有不同,但是底层的原则相通的。
可选值的约定
Swift 提供了 Optional 数据类型,这迫使我们显式地思考和处理没有值的情况。我们非常喜欢这个功能,所以我们在所有的例子里都使用了它。
因此我们尽量避免使用 Swift 的 ! 操作符来强制解包 (包括用它来定义隐式解包类型的用法),在我们看来这是一种坏代码的味道,因为它破坏了我们使用可选值类型所带来的类型安全。
唯一的例外是那些必须设置但又无法在初始化时设置的属性。比如 Interface Builder 的 outlets 或必要的代理 (delegate) 属性等。在这些情况下,使用隐式解包的可选值符合 “尽早崩溃” 原则:我们会立刻知晓这些必须要设置而又没有正确设置的属性。
错误处理的约定
Core Data 中好些方法会抛出错误。基于它们是不同类型的错误的这一基本事实,我们可以分类处理这些错误。我们将区分逻辑错误和其他错误。
逻辑错误是指程序员犯错的结果。它们应该从代码层面上修复而不应该尝试动态恢复程序的运行。
一个例子,当你尝试读取应用程序包里的一个文件的时候,因为应用程序包是只读的,那么一个文件要么存在要么不存在,而且它的内容永远不会变。所以如果我们无法打开或者解析应用程序包里的文件,这就是一个逻辑错误。
对于这些类型的错误,我们使用 Swift 的 try! 或 fatalError() 来尽可能早地让应用程序崩溃。
同样的思想可以适用于 as! 操作符的强制类型转换: 如果我们知道一个对象必须是某种类型,转换失败的唯一原因会是逻辑错误,这种时候我们实际上是希望应用程序崩溃的。
很多时候我们用 Swift 的 guard 关键字来更好地表达哪些地方出错了。举个例子,如果我们知道托管对象的 managedObjectContext 属性一定是非 nil 的,那么我们就可以使用一个 guard let 声明语句,并在 else 分支里显式地调用 fatalError。这比直接强制解包更能清楚地表达我们的意图。
对于可恢复的非逻辑性错误,我们使用 Swift 的错误传递方法:抛出 (throw) 或者重新抛出 (rethrow) 这些错误。
译序
上世纪六十年代中,导航式数据库的概念随着磁盘直接存取而发展起来;七十年代开始,关系型数据库登上历史舞台,它的概念一直延续至今。我们无法想象现代的计算机程序中离开了数据库会是怎样的景象,数据库技术已经成为了这个世界方方面面的基石。
在数据管理和数据库相关的方面,Apple 给出的选择是 Core Data。正如在简介中所提到的那样,Core Data 其实并不是一个传统意义上的数据库,而是一套对象图管理系统。这套系统默认使用 SQLite 作为底层存储,通过由低向高地将相关的管理组件构建为一个栈,来提供缓存和对象管理机制。这让我们对于数据对象的存储和访问都能够高效而有序地进行。从这一点上来说,Core Data 与单纯的数据库相比,实在是强大得多。
但是能力越大,责任也越大。如果使用不当,Core Data 不但不能为你提供良好的数据存储和访问的性能,甚至会连最基本的操作都难以保证。在这种情况下,Core Data 将不再是你开发的助力,反而会成为掣肘。不幸的是,Core Data 本身学习曲线比较陡峭,而涉及的概念又非常多,所以真正想要精通 Core Data 并完全发挥它的效能并不是很容易的事情。
Apple 在 iOS 的很多原生应用中大量使用了 Core Data,比如照片、音乐和 iBooks 等,并且事实证明它们都出色地完成了任务。在国外,也有很多开发者使用 Core Data 作为应用程序的数据层和持久化的选择。相比于其他第三方的解决方案,Core Data 不需要引入额外的框架,也相对稳定可靠。但是在国内,现在使用这项技术的开发者较少,大家对 Core Data 的研究也普遍没有国外深入,这导致了提到 Core Data 很多人会不自觉地抗拒和躲避。将 Core Data 的使用方法和最佳实践以更容易理解的方式带给国内开发者,促进大家接触 Core Data 的架构和思想,这正是我们选择翻译本书的目的。
本书的结构和阅读方法已经在简介中有所说明,就不再赘述了。需要补充的是,这本书里提供了大量的例子和相应的代码,它们大多是需要进行权衡的选择,并对应了不同的场景。只有在你充分理解这些例子的含义后,你才可能在实际使用时作出正确的判断。另外,Core Data 的灵活性是一把双刃剑,当你选择了更多的上下文以及协调器时,也意味着你为项目引入了更多的复杂度。尽可能在能够满足需求的前提下,选择最简单的 Core Data 栈设置,是高效正确使用 Core Data 的关键。
本书原版的两位作者有着多年的 Core Data 使用经验。Florian Kugler 是 objc.io 的联合创始人,曾经为 objc.io 撰写了很多 Core Data 相关的文章,深受读者喜爱。Daniel Eggert 曾供职于 Apple,帮助 Apple 将照片应用迁移到 Core Data 框架内。他们的努力让 Core Data 这个看起来有些“可怕”的框架变得平易近人,籍此我们可以一窥 Core Data 的究竟。不过不论是原作者还是译者,其实和各位读者一样,都只不过是普通开发者中的一员,所以本书出现谬漏可能在所难免。如果您在阅读时发现了问题,可以给我们发邮件,或是在本书 issue 页面提出,我们将及时研究并加以改进。
最后,祝您阅读愉快。
徐涛,钱世家,王巍
初探 Core Data
在本章中,我们将创建一个简单的使用 Core Data 的示例程序。在这个过程中,我们会介绍 Core Data 的基本架构以及在此场景下如何正确使用它。当然,这一章提到的方方面面都有更多值得一谈的内容。不过请放心,后面我们将会详细回顾这些内容。
本章会介绍这个示例程序中与 Core Data 相关的所有方面的内容。请注意这并不是一个从头开始一步一步教你如何创建整个应用的教程。我们推荐你看一下在 GitHub 上完整的代码来在实际项目中了解不同的部分。
这个示例应用程序包括一个简单的 table view 和底部的实时摄像头拍摄的内容。拍摄一张照片后,我们从照片中提取出它的一组主色。然后存储这些配色方案 (我们称其为 “mood”),并相应地更新 table view。
示例应用程序 - “Moody”
Core Data 架构
为了更好的理解 Core Data 的架构,在我们开始创建这个示例应用之前,让我们先来看看它的主要组成部分。我们将会在第二部分中详细介绍所有这些部分是如何协同工作的。
一个基本的 Core Data 栈由四个主要部分组成:托管对象 (managed objects) (NSManagedObject),托管对象上下文 (managed object context) (NSManagedObjectContext),持久化存储协调器 (persistent store coordinator) (NSPersistentStoreCoordinator),以及持久化存储 (persistent store) (NSPersistentStore):
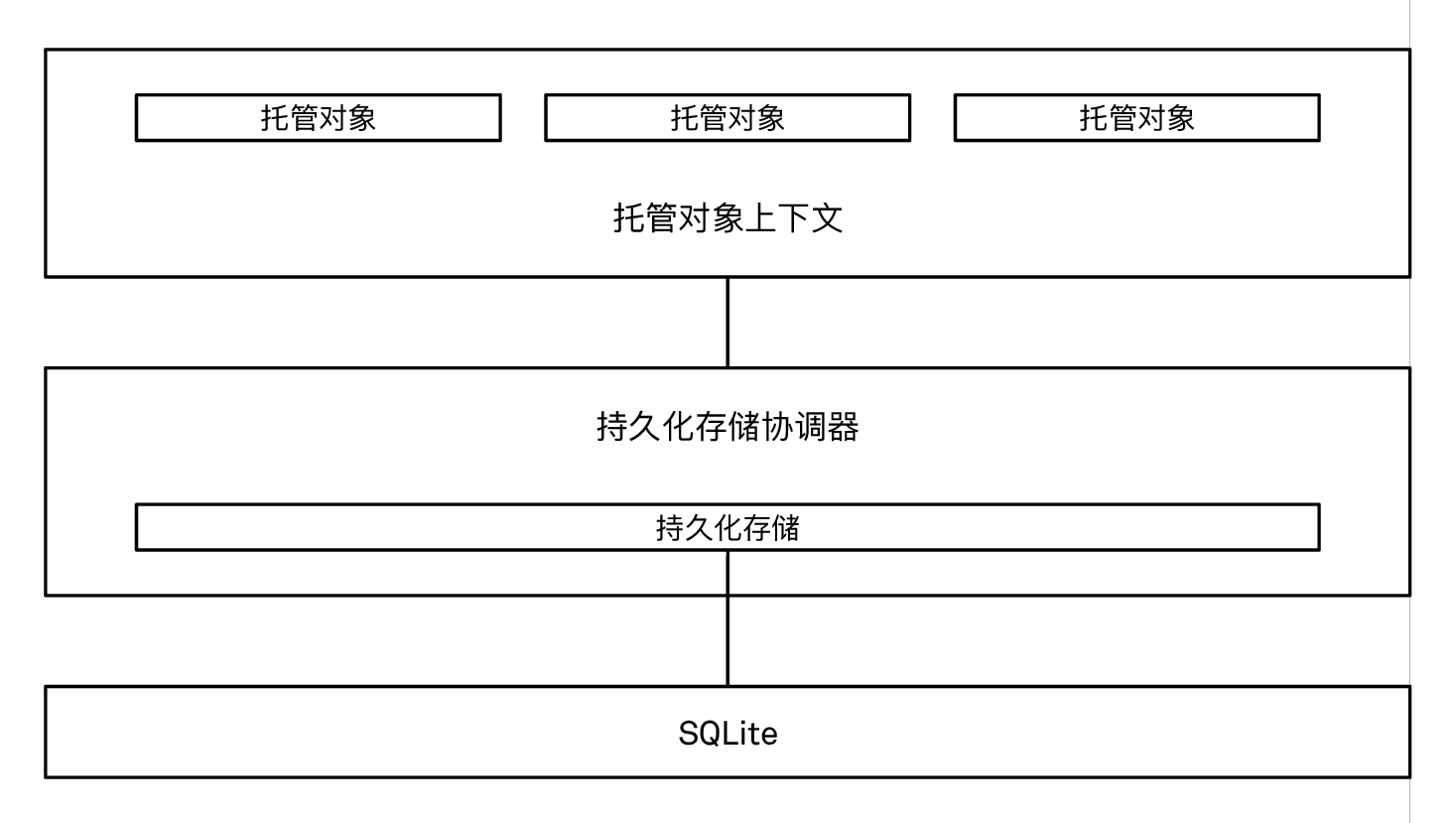
Core Data 栈的基本组成部分
托管对象位于这张图的最上层,它是架构里最有趣的部分,同时也是我们的数据模型 - 在这个例子里,它是 Mood 类的实例们。Mood 需要是 NSManagedObject 类的子类,这样它才能与 Core Data 其他的部分进行集成。每个 Mood 实例表示了一个 mood,也就是用户用相机拍摄的照片。
我们的 mood 对象是被 Core Data 托管的对象。也就是说,它们存在于一个特定的上下文 (context) 里:那就是托管对象上下文。托管对象上下文记录了它管理的对象,以及你对这些对象的所有操作,比如插入,删除和修改等。每个被托管的对象都知道自己属于哪个上下文。Core Data 支持多个上下文,但是我们先别好高骛远:我们先像本章中最简单的设置这样,只使用一个单独的上下文。
上下文与持久化存储协调器相连,协调器位于持久化存储和托管对象上下文之间。对于本章中的这个简单例子,我们不用太关心持久化存储协调器或者持久化存储,因为 NSPersistentContainer 这个辅助类会帮助我们把它们都设置好。可以这么说,默认情况下 Core Data 会使用一个 SQLite 类型的持久化存储,也就是说你的数据在底层实际上会被存储在一个 SQLite 数据库里。Core Data 也提供其他的存储类型 (比如 XML,二进制数据,内存),但是现在我们不需要考虑其他的存储类型。
我们将在第二部分的访问数据这一章中再详细讨论 Core Data 栈中所有部分的内容。
数据建模
Core Data 存储结构化的数据。所以为了使用 Core Data,我们首先需要创建一个数据模型 (或者是大纲 (schema),如果你乐意这么叫它的话) 来描述我们的数据结构。
你可以通过代码来定义一个数据模型。但是使用 Xcode 的模型编辑器创建和编辑 .xcdatamodeld 文件会更容易。在你开始用 Xcode 模板创建新的 iOS 或 macOS 应用程序时候,你可以在 File > New 弹出的菜单里的 Core Data 部分中选择 “Data Model” 来创建一个数据模型。如果你在第一次创建项目时勾上了 “Use Core Data” 这个选项,Xcode 将为你创建一个空的数据模型。
事实上,你并不需要通过勾上 “Use Core Data” 选项来使用 Core Data - 相反,我们建议你不要这么做,因为我们之后会把生成的模板代码都删掉。
如果你在 Xcode 的 project navigator 里选中了数据模型文件,Xcode 的数据模型编辑器就会打开,我们就可以开始工作了。
实体和属性
实体 (entity) 是数据模型的基石。正因为如此,一个实体应该代表你的应用程序里有意义的一部分数据。例如,在我们的例子里,我们创建了一个叫 Mood 的实体,它有两个属性:一个代表颜色,一个代表拍摄照片的日期。按照惯例,实体名称以大写字母开头,这和类的名称的命名方式类似。
Core Data 自身就支持很多数据类型:数值类型 (整数和不同大小的浮点数,以及十进制数值),字符串,布尔值,日期,二进制数据,以及存储着实现了 NSCoding 协议的对象或者是提供了自定义值转换器 (value transformer) 的对象的可转换类型。
对于 Mood 实体,我们创建了两个属性:一个是日期类型 (被称为 date),另一个是可转换类型 (被称为 colors)。属性的名称应该以小写字母开头,就像类或者结构体里的属性一样。colors 属性是一个数组,里面都是 UIColor 对象,因为 NSArray 和 UIColor 已经遵循了 NSCoding 协议,所以我们可以把这样的数组直接存入一个可转换类型的属性里:
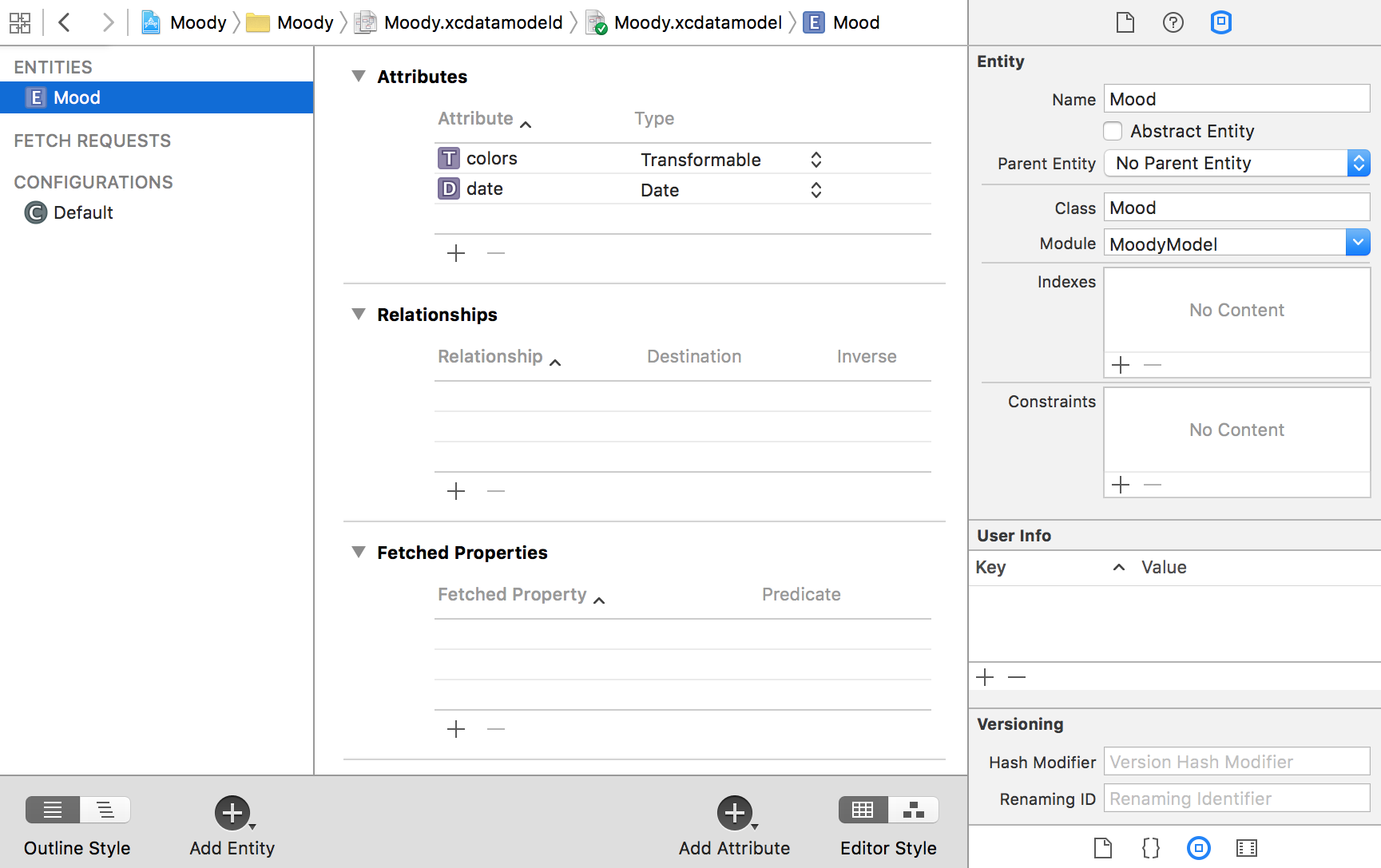
在 Xcode 模型编辑器里的 Mood 实体
属性选项
两个属性都有更多的一些选项可以让我们调整。我们把 date 属性标记为必选的 (non-optional) 和可索引的 (indexed)。colors 数组也标记为必选属性。
必选属性必须要赋给它们恰当的值,才能保存这些数据。把一个属性标记为可索引时,Core Data 会在底层 SQLite 数据库表里创建一个索引。索引可以加速这个属性的搜索和排序,但代价是插入数据时的性能下降和额外的存储空间。在我们的例子里,我们会以 mood 对象的时间来排序,所以把 date 属性标记为可索引是有意义的。我们后面会在性能和性能分析这些章节里深入探讨这个主题。
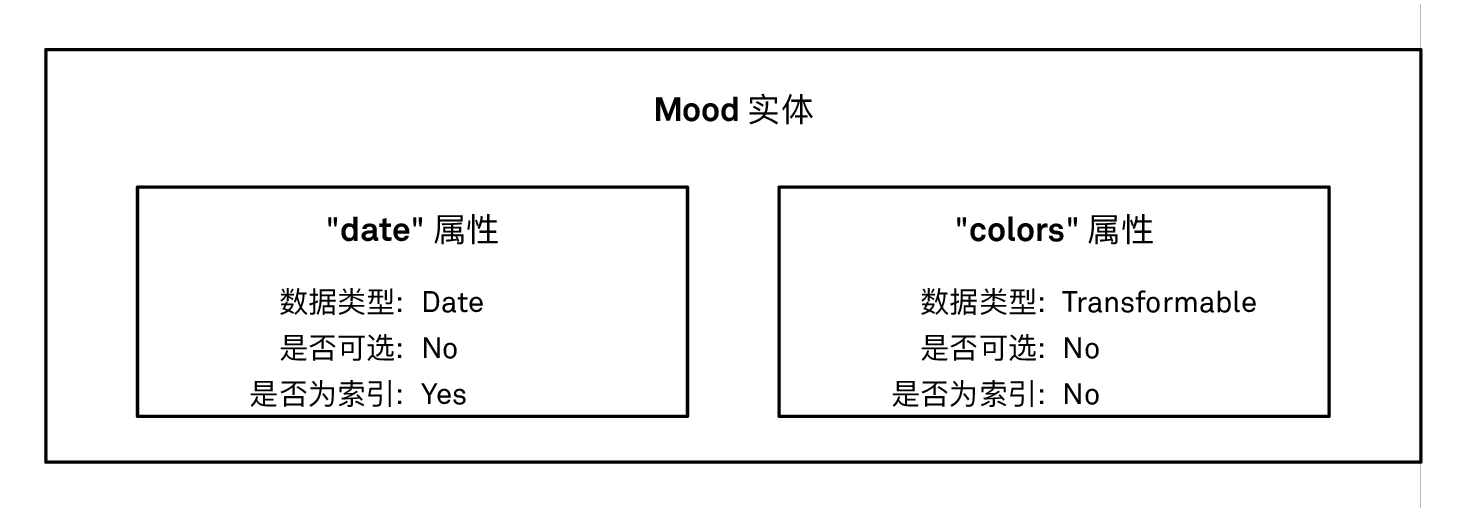
Mood 实体的属性
托管对象子类
现在我们已经创建好了数据模型,我们需要创建代表 Mood 实体的托管对象子类。实体只是描述了哪些数据属于 mood 对象。为了在代码中能使用这个数据,我们需要一个具有和实体里定义的属性们相对应的属性的类。
一个好的实践是按它们所代表的东西来命名这些类,并且不用添加类似 Entity 这样的后缀。比如,我们的类直接叫 Mood 而不是 MoodEntity。实体和类都叫 Mood,非常完美。
对于创建类,我们建议不要使用 Xcode 的代码生成工具 (Editor > Create NSManagedObject Subclass...) ,而是直接手写它们。到最后,你会发现你每次只需要写很少几行代码,就能带来完全掌控它们的好处。此外,手写代码还会让整个流程变得更加清楚,你会发现其中并没有什么魔法。
我们的 Mood 实体在代码里是像这样的:
final class Mood: NSManagedObject {
@NSManaged fileprivate(set) var date: Date
@NSManaged fileprivate(set) var colors: [UIColor]
}
修饰 Mood 类属性的 @NSManaged 标签告诉编译器这些属性将由 Core Data 来实现。Core Data 用一种很不同的方式来实现它们,我们会在第二部分里详细谈论这部分内容。fileprivate(set) 这个访问控制修饰符表示这两个属性都是公开只读的。Core Data 其实并不强制执行这样的只读策略,但我们在类中定义了这些标记,于是编译器将保证它们是公开只读的。
在我们的例子里,没必要将之前提到的属性标记为公开可写。我们会创建一个辅助方法来插入以特定值创建的新的 mood 对象,而之后,我们就再也不会修改这些值了。所以一般而言,最好的做法是,只有当你真正需要的时候,才把对象里的属性和方法公开地暴露出来。
为了能让 Core Data 识别我们的 Mood 类,并把它和 Mood 实体相关联,我们在模型编辑器里选中这个实体,然后在 data model inspector 里输入它的类名。
设置 Core Data 栈
现在我们有第一个版本的数据模型和 Mood 类了,我们可以使用 NSPersistentContainer 来设置一个基本的 Core Data 栈。我们将使用如下的方法来创建这个容器,从中我们可以获取将在整个 app 里都被使用的托管对象上下文:
func createMoodyContainer(completion:
@escaping (NSPersistentContainer) -> ())
{
let container = NSPersistentContainer(name: "Moody")
container.loadPersistentStores { _, error in
guard error == nil else { fatalError("Failed to load store: \(error)") }
DispatchQueue.main.async { completion(container) }
}
}
让我们一步一步分析上面的代码。
首先,我们创建并命名了一个持久化容器 (persistent container)。Core Data 使用这个名字来查找对应的数据模型,所以它应该和你的 .xcdatamodeld bundle 的文件名一致。接下来,我们调用容器的 loadPersistentStores 方法来尝试打开底层的数据库文件。如果数据库文件还不存在, Core Data 会根据你在数据模型里定义的大纲 (schema) 来生成它。
因为持久化存储们 (在我们的例子里,以及大多数真实世界情况下,只会有一个存储) 是异步加载的 ,一旦一个存储被加载完成,我们的回调就会被执行。如果发生了一个错误,我们现在就直接让程序崩溃掉。在生产环境中,你可能需要采取不同的反应,比如迁移已有的存储到新的版本,或者作为最后的手段,删除并重新创建这个存储。
最后,我们调度回主队列,并用这个新的持久化容器作为参数,调用 createMoodyContainer 的完成处理函数。
因为我们已经把这些模板代码都封装到了一个简洁的辅助方法里,我们可以在应用程序代理 (application delegate) 里通过一个简单的 createMoodyContainer() 方法调用来初始化持久化容器:
class AppDelegate: UIResponder, UIApplicationDelegate {
var persistentContainer: NSPersistentContainer!
var window: UIWindow?
func application(_ application: UIApplication,
didFinishLaunchingWithOptions
launchOptions: [UIApplicationLaunchOptionsKey: Any]?)
-> Bool
{
createMoodyContainer { container in
self.persistentContainer = container
let storyboard = self.window?.rootViewController?.storyboard
guard let vc = storyboard?.instantiateViewController(
withIdentifier: "RootViewController")
as? RootViewController
else { fatalError("Cannot instantiate root view controller") }
vc.managedObjectContext = container.viewContext
self.window?.rootViewController = vc
}
return true
}
}
一旦我们接收持久化容器参数的回调被执行,我们就把这个容器存储在一个属性里。然后我们把应用程序启动时加载的初始 view controller (只是在我们加载完存储前用来占位的) 替换成我们 app 的 root view controller。我们从 storyboard 里初始化这个 root view controller,把托管对象上下文赋值给它,并把它设置成 window 的 root view controller。
显示数据
现在我们已经初始化好了 Core Data 栈,接下来我们可以使用在应用程序代理里创建的托管对象上下文来查询我们需要显示的数据了。
为了方便在 view controller 里使用这个托管对象上下文,我们在应用程序代理里把这个上下文对象传递给第一个 view controller,然后通过它再传递给视图层次里其他需要访问这个上下文的 view controller。比如在 prepareForSegue 方法里,root view controller 把这个上下文传给了 MoodTableViewController:
override func prepare(for segue: UIStoryboardSegue,
sender: Any?)
{
switch segueIdentifier(for: segue) {
case .embedNavigation:
guard let nc = segue.destination
as? UINavigationController,
let vc = nc.viewControllers.first
as? MoodsTableViewController
else { fatalError("wrong view controller type") }
vc.managedObjectContext = managedObjectContext
// ...
}
}
// ...
这个模式和我们在应用程序代理里做的非常类似,不同的是现在我们需要先遍历 navigation controller 来拿到 MoodsTableViewController 实例。
如果你对 segueIdentifier(for:) 这个方法的由来感到好奇,可以参考 WWDC 2015 的 Swift in Practice 这个 session,我们参考了里面的这个模式。这是在 Swift 里使用协议扩展 (protocol extension) 的绝好例子,它让 segue 变得更加显式,还可以让编译器检查我们是否处理了所有的情况。
为了展示 mood 对象 - 虽然我们现在还没有数据,我们可以先剧透一点 - 我们会使用 table view 与 Core Data 的 NSFetchedResultsController 的组合来显示数据。这个类会监听我们数据集的变化,然后以一种非常容易就可以更新对应的 table view 的方式来通知我们这些变化。
获取请求
顾名思义,一个获取 (Fetch) 请求描述了哪些数据需要被从持久化存储里取回,以及它们是如何被取回的。我们会使用获取请求来取回所有的 Mood 实例,并把它们按照创建时间进行排序。获取请求还可以设置非常复杂的过滤条件,并只取回一些特定的对象。事实上,由于获取请求如此之强大,我们后面再详细讨论它们能做什么。
需要指出的重要一点是:每次你执行一个获取请求,Core Data 会穿过整个 Core Data 栈,直到文件系统。按照 API 约定,获取请求就是往返的:从上下文,经过持久化存储协调器和持久化存储,降入 SQLite,然后原路返回。
虽然获取请求是强力的工具,但是它们需要做很多的工作。执行一个获取请求是个相对昂贵的操作。我们会在第二部分里详细讨论具体原因以及如何避免掉这些开销。但是现在,我们只要记住,要慎重地使用获取请求,因为它们可能是一个潜在的性能瓶颈。通常,我们可以通过遍历关系来避免使用获取请求,我们后面还会提到这些内容。
让我们回到我们的例子里。这里演示了我们如何创建一个获取请求来从 Core Data 里取回所有的 Mood 实例,并按它们的创建时间降序排列 (我们很快会整理这部分代码):
let request = NSFetchRequest<Mood>(entityName: "Mood")
let sortDescriptor = NSSortDescriptor(key: "date", ascending: false)
request.sortDescriptors = [sortDescriptor]
request.fetchBatchSize = 20
这个 entityName 参数是我们的 Mood 实体在数据模型里的名称。而 fetchBatchSize 属性告诉 Core Data 一次只获取特定的数量的 mood 对象。这背后其实发生了许多“魔法”;我们会在访问数据章节里深入了解这些机制。我们设置的获取批次大小为 20,这大约也是屏幕能显示项数的两倍。我们会在性能这一章节里继续探讨如何调整批次大小的问题。
简化模型类
在我们继续开始使用这个获取请求之前,我们会先给模型类添加一些方法,让之后的代码变得更容易使用和维护。
我们会演示一种创建获取请求的方式,它能更好地将关注点进行分离 (separation of concerns, SoC)。之后我们在扩展示例程序其他方面的时候这个模式也能派上用场。
译者注:关注点分离,是面向对象的程序设计的核心概念。分离关注点使得解决特定领域问题的代码从业务逻辑中独立出来,业务逻辑的代码中不再含有针对特定领域问题代码的调用 (将针对特定领域问题代码抽象化成较少的程式码,例如将代码封装成类或是函数),业务逻辑同特定领域问题的关系被封装,易于维护,这样原本分散在在整个应用程序中的变动就可以很好地被管理起来。
在 Swift 中,协议扮演了核心角色。我们会给 Mood 模型添加并实现一个协议。事实上,我们后面添加的模型类都会实现这个协议 - 我们建议在你的模型类里也这么做:
protocol Managed: class, NSFetchRequestResult {
static var entityName: String { get }
static var defaultSortDescriptors: [NSSortDescriptor] { get }
}
我们将利用 Swift 的协议扩展来为 defaultSortDescriptors 添加一个默认的实现,同时也作为这个实体的一个使用默认排序描述符的获取请求的计算属性 (computed property):
extension Managed {
static var defaultSortDescriptors: [NSSortDescriptor] {
return []
}
static var sortedFetchRequest: NSFetchRequest<Self> {
let request = NSFetchRequest<Self>(entityName: entityName)
request.sortDescriptors = defaultSortDescriptors
return request
}
}
此外,我们将通过约束为 NSManagedObject 子类型的协议扩展来给静态的 entityName 属性添加一个默认实现:
extension Managed where Self: NSManagedObject {
static var entityName: String { return entity().name! }
}
现在我们让 Mood 类遵循 Managed 协议,并为 defaultSortDescriptors 提供了一个特殊实现:我们希望 Mood 的实例默认按日期排序 (就像在我们之前创建的获取请求里做的那样):
extension Mood: Managed {
static var defaultSortDescriptors: [NSSortDescriptor] {
return [NSSortDescriptor(key: #keyPath(date), ascending: false)]
}
}
通过这个扩展,我们可以像这样来创建和上面相同的获取请求:
let request = Mood.sortedFetchRequest
request.fetchBatchSize = 20
我们后面会以这个模式为基础,给 Managed 协议添加更多的便利方法 - 比如,创建获取请求的时候指定谓词 (predicate) 或者是搜索这个类型的对象。你可以参考示例代码里的 Managed 协议的所有扩展方法和属性。
现在,我们看上去似乎做了很多不必要的工作。但这其实是一种非常干净的设计,也是一个值得依赖的良好基础。随着我们的 app 变得越来越复杂,我们会更多地使用这个模式。
Fetched Results Controller
我们使用 NSFetchedResultsController 类来协调模型和视图。在我们的例子里,我们用它来让 table view 和 Core Data 中的 mood 对象保持一致。fetched results controller 还可以用于其他场景,比如在使用 collection view 的时候。
使用 fetched results controllers 的主要优势是:我们不是直接执行获取请求然后把结果交给 table view,而是在当底层数据有变化的时候,它能通知我们,让我们很容易地更新 table view。为了做到这一点,fetched results controllers 监听了一个通知,这个通知会由托管对象上下文在它之中的数据发生改变的时候所发出 (修改和保存数据这一章会更多有关于这方面的内容)。fetched results controllers 会根据底层获取请求的排序,计算出哪些对象的位置发生了变化,哪些对象是新插入的等等,然后把这些改动报告给它的代理:
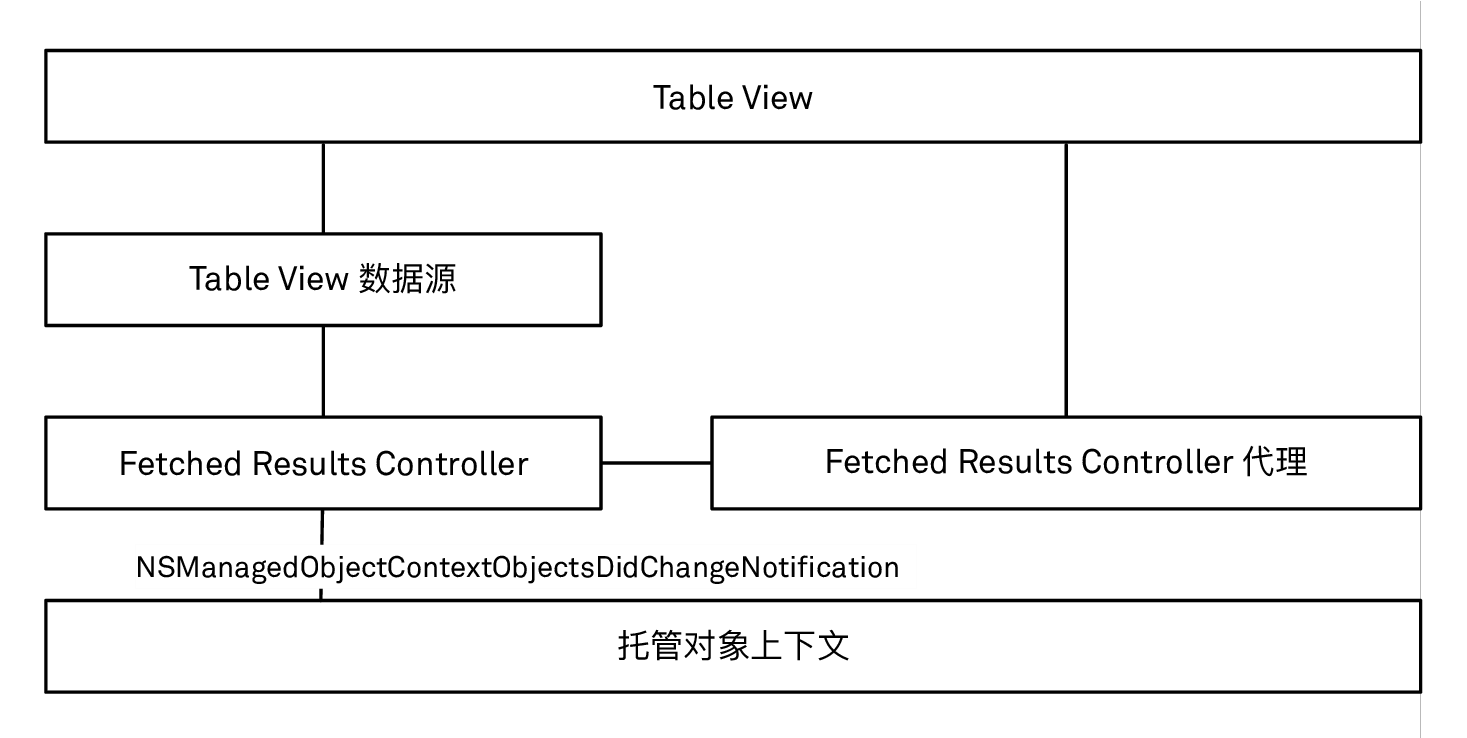
fetched results controller 与 table view 是如何交互的
为了初始化 mood table view 的 fetched results controller,我们在 UITableViewController 子类的 viewDidLoad 方法里调用了 setupTableView 这个方法。setupTableView 使用了前面提到的获取请求来创建一个 fetched results controller:
fileprivate func setupTableView() {
// ...
let request = Mood.sortedFetchRequest
request.fetchBatchSize = 20
request.returnsObjectsAsFaults = false
let frc = NSFetchedResultsController(fetchRequest: request,
managedObjectContext: managedObjectContext,
sectionNameKeyPath: nil, cacheName: nil)
// ...
}
一个 fetched results controller 的代理需要实现如下的三个方法,它们会在底层数据发生变化的时候通知我们 (从技术上来讲,你可以“偷懒”,只实现最后一个方法,但这样会违背我们使用 fetched results controller 的初衷) :
controllerWillChangeContent(_:)controller(_:didChange:at:for:newIndexPath:)controllerDidChangeContent(_:)
我们可以在 view controller 的类里直接实现上面的这些方法。但是这样的模板代码会把 view controller 弄得很乱,而且我们不得不在每个需要使用 fetched results controller 的 view controller 里重复所有这样的模板代码。所以,我们打算从一开始就把这些给做对,把 fetched results controller 的代理方法的实现封装进可以复用的一个类里,同时这个类可以作为 table view 的数据源 (data source)。我们在 view controller 的 setupTableView 方法里初始化这样一个实例:
fileprivate func setupTableView() {
// ...
dataSource = TableViewDataSource(
tableView: tableView, cellIdentifier: "MoodCell",
fetchedResultsController: frc, delegate: self)
}
在初始化的时候,TableViewDataSource 把自己设置成了 fetched results controller 的代理以及 table view 的数据源。然后它调用 performFetch(_:) 方法从持久化存储中加载这些数据。由于这个方法可能会抛出错误,所以我们在它前面加了 try! 关键词来让它尽早的崩溃,因为这是一个编程上的错误:
class TableViewDataSource<Delegate: TableViewDataSourceDelegate>:
NSObject, UITableViewDataSource, NSFetchedResultsControllerDelegate
{
typealias Object = Delegate.Object
typealias Cell = Delegate.Cell
required init(tableView: UITableView, cellIdentifier: String,
fetchedResultsController: NSFetchedResultsController<Object>,
delegate: Delegate)
{
self.tableView = tableView
self.cellIdentifier = cellIdentifier
self.fetchedResultsController = fetchedResultsController
self.delegate = delegate
super.init()
fetchedResultsController.delegate = self
try! fetchedResultsController.performFetch()
tableView.dataSource = self
tableView.reloadData()
}
// ...
}
这里的 NSFetchedResultsControllerDelegate 方法只包含与 table view 交互的标准模板代码。请在示例工程里查看这个类的完整代码。
当 fetched results controller 和它的代理都就位后,我们就可以继续下一步了:让 table view 里实际地显示出数据。为此,我们在自定义的 TableViewDataSource 类里实 现必要的两个 table view 数据源方法。在这些方法里,我们使用 fetched results controller 来获取所需的数据:
func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int)
-> Int
{
guard let section = fetchedResultsController.sections?[section]
else { return 0 }
return section.numberOfObjects
}
func tableView(_ tableView: UITableView,
cellForRowAt indexPath: IndexPath) -> UITableViewCell
{
let object = fetchedResultsController.object(at: indexPath)
guard let cell = tableView.dequeueReusableCell(
withIdentifier: cellIdentifier, for: indexPath) as? Cell
else { fatalError("Unexpected cell type at \(indexPath)") }
delegate.configure(cell, for: object)
return cell
}
在 tableView(_:cellForRowAt:) 方法里,我们请求 TableViewDataSource 的代理来配置一个特定的 cell。通过这种方式,我们可以在 app 里的其他 table view 里复用 TableViewDataSource 这个类,因为它并没有包含任何只限定于 moods table view 里的代码。moods view controller 是通过传递 Mood 实例给 cell 的 configure 方法来实现这个代理方法的。
extension MoodsTableViewController: TableViewDataSourceDelegate {
func configure(_ cell: MoodTableViewCell, for object: Mood) {
cell.configure(for: object)
}
}
你可以在 GitHub 上查看这个 table view cell 的详细代码。
我们已经走了很远了。我们创建了模型,设置了 Core Data 栈,在 view controller 层级里传递托管对象上下文,我们创建了获取请求,然后用 fetched results controller 来让 table view 展示数据。现在唯一缺失的部分是显示所需的实际数据,让我们继续讨论它吧。
操作数据
总结
iOS 10/macOS 10.12 之前的版本需要注意的地方
关系
在本章中,我们通过添加两个新的实体:Country (国家) 和 Continent (大陆) 来扩展我们的数据模型。在这个过程中,我们会解释子实体 (subentities) 的概念,并且讨论你什么时候应该以及什么时候不应该使用它们。在这之后我们会建立这三个实体之间的关系。关系是 Core Data 的一个关键特性,我们将使用关系把每个 mood 和一个 country、以及每个 country 和一个 continent 联系起来。
你可以在 GitHub 上查看我们在本章中使用的示例工程的完整源代码。
添加更多实体
创建关系
其他类型的关系
建立关系
关系和删除
适配用户界面
总结
数据类型
在本章中,我们会更仔细地看看 Core Data 直接支持的数据类型。我们还会讨论如何用不同的方式来存储自定义数据类型,包括在方便性,数据大小和性能之间的权衡。
标准数据类型
原始属性和临时属性
自定义数据类型
默认值和可选值
总结
访问数据
在本章中,我们将深入了解 Core Data 的各个部分在你以不同方式访问持久化的数据时是如何协作的。我们还将看看如何利用 Core Data 提供的高级选项来获得对整个流程更多的控制。接着,我们会讨论所有这些机制之所以存在的一个主要原因:那就是为了有效利用内存和提高性能。为了能让你处理巨大的数据集,Core Data 其实做了很多繁重的工作。
在简单的使用场景下,你并不需要知道这些也能使用 Core Data。但是如果能理解 Core Data 背后的原理,它就能在你处理更复杂的或者是大规模的 (包含成千上万个对象) 设置时带来帮助。
贯穿整章,假设我们都会使用默认的 SQLite 持久化存储。
获取请求
获取请求 (Fetch Requests) 是最显而易见的从 Core Data 里获取对象的方式。让我们来看看,在你执行一个非常简单的、没有修改任何配置选项的获取请求时会发生什么:
let request = NSFetchRequest<Mood>(entityName: "Mood")
let moods = try! context.fetch(request)
让我们一步一步地分析:
上下文通过调用
execute(_ request :with context:)方法把获取请求转交给它的持久化存储协调器。请注意这里上下文将自己作为第二个参数传入 - 它在后面会被使用到。持久化存储协调器通过调用每个存储上的
execute(_ request:with context:)方法将获取请求转发给所有的持久化存储们 (假如你有多个存储的话)。再次注意:发起获取请求的上下文被传递给了持久化存储。持久化存储把获取请求转换成一个 SQL 语句,并把这个 SQL 语句发送给 SQLite。
SQLite 在存储的数据库文件里执行这个语句,并将所有匹配查询条件的所有行 (row) 返回给存储 (更多细节具体可以参考 SQLite 一章)。这些行同时包含了对象的 ID (Object ID) 和属性的数据 (因为获取请求的
includesPropertyValues选项默认值是true)。对象的 ID 是存储里记录的唯一标识 — 事实上,它们是持久化存储的 ID、表的 ID 以及表中行的主键的一个组合。返回的原始数据是由数字、字符串和二进制大对象 (BLOB, Binary Large Objects) 这样的简单的数据类型组成的。它被存储在持久化存储的行缓存 (row cache) 里,一起存储的还有对象 ID 和缓存条目最后更新的时间戳。只要在上下文里存在某个特定对象 ID 的托管对象,含有这个对象 ID 的行缓存条目就会一直存在,无论这个对象是不是惰值 (fault)。
持久化存储把它从 SQLite 存储接收到的对象 ID 实例化为托管对象,并把这些对象返回给协调器。为了实现这个目的,存储需要调用上下文的
object(with:)方法,因为托管对象们都是被绑定到一个特定的上下文里的。获取请求的默认行为是返回托管对象 (其实还可以是其他的结果类型 (result types),不过我们暂时不考虑它们)。这些对象默认是惰值,也就是一些没有填充实际数据的轻量级对象。它们承诺会在你需要的时候去加载数据 (后面会介绍更多关于惰值的内容)。
但是,如果上下文里已存在具有相同的对象 ID 的对象,那么这个已有的对象将会被使用。这就是所谓的唯一性:Core Data 保证在一个托管对象上下文里,无论你通过什么方式,只会得到唯一一个表示某块数据的对象。换句话来说:也就是在相同的托管对象上下文里,表示相同数据的对象的指针地址也是相等的。
持久化存储协调器把它从持久化存储拿到的托管对象数组返回给上下文。
因为获取请求的
includesPendingChanges属性默认值是true,在返回获取请求的结果之前,上下文会将那些正在等待进行的更改考虑进来,并相应地更新原来的结果。(等待进行的更改是指那些你在托管对象上下文里做过但是还没被保存的更新、插入或者删除操作)。结果里可能会添加了一些额外的对象,或者会有对象因为不再匹配查询条件而被移除。最后,一个匹配该获取请求的托管对象数组被返回给调用者。
所有的一切操作都是同步发生的,而且直到获取请求完成为止,托管对象上下文都会被阻塞。在 iOS 10/macOS 10.12 之前的版本里,持久化存储协调器也会被阻塞。
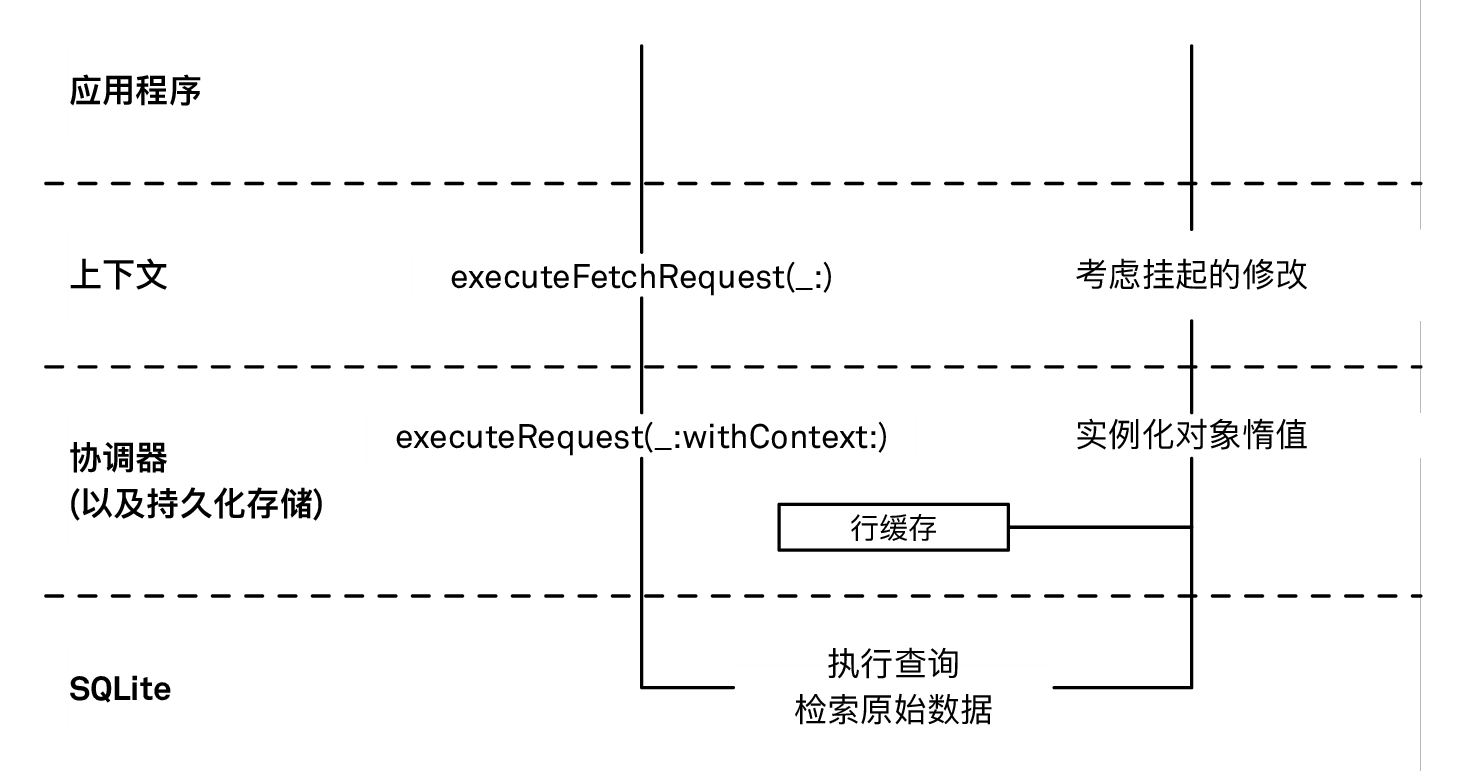
一个获取请求会一直降入到 SQLite 存储并往返
现在,你有了一个托管对象数组,用来表征你在获取请求里要求的数据。但是,由于这些对象是惰值,在你实际访问这些对象的数据时还会发生一些其他事情。我们将在下一小节里讨论它们。
在这个过程中,最重要的部分是 Core Data 的惰值化和唯一性机制。惰值允许你无需在内存中实体化所有对象就能处理大数据集;唯一性可以确保对于相同的数据,你总是得到相同的对象,并且有且仅有一个对象副本。
关系
其他取回托管对象的方法
内存考量
总结
更改和保存数据
在本章中,我们将深入探讨当你在更改数据时,Core Data 栈中会发生什么。上至冲突检测时对数据变更进行追踪,下到对数据进行持久化处理,都将涉及到对数据的更改。此外,我们还将着眼于一些能一次性修改多个对象的高级 API,并探讨它们的工作原理以及如何正确地使用它们。
和前面的章节一样,假设我们使用的是默认的 SQLite 持久化存储。
变更追踪
保存更改
批量更新
总结
性能
在前面的一些章节中,我们探讨了很多关于 Core Data 内部是如何工作的内容。本章我们将从性能方面来对这些内部内容进行探讨,还会了解如何应用这些知识来让 Core Data 高性能地工作。
需要注意的是性能并不仅仅是指运行速度。通过性能调优可以确保你的 app 能快速运行,动画流畅,用户操作不需要等待。此外性能还包括能耗:你调优 app 的性能的同时你也改善了电池寿命。同样的优化对能耗和速度都有影响。确保你的 app 在一台较慢的设备上流畅运行同样能让使用更新更快设备的用户受益,因为它的电池寿命将会更久。
Core Data 栈的性能特质
一个主要的性能提升来源是,理解并正确地应用 Core Data 栈的性能特质:
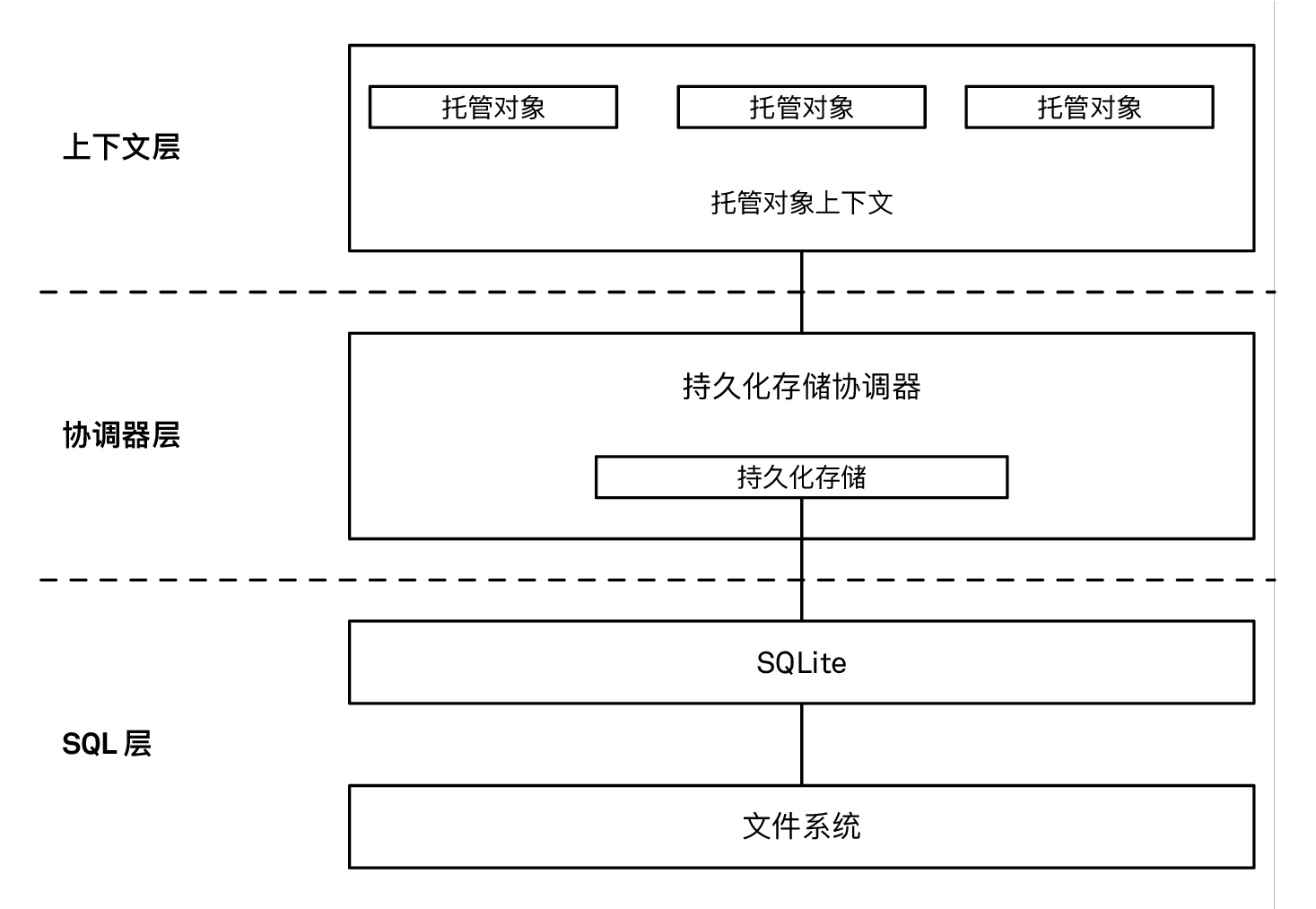
Core Data 栈的不同层级有不同的性能特质
我们可以大致的把 Core Data 栈分成三层。顺着栈从上往下看,每往下一层的复杂度都指数级增加 - 即对性能的影响会显著的提高。这是一个极度简化但同时却能帮助我们理解 Core Data 性能测试的强大的心智模型 (mental model)。
栈的顶层是托管对象和对应的上下文。只要我们的操作能停留在这一层,速度将会非常快。往下一层是持久化存储协调器及其行缓存 (row cache),最后是 SQL 层和文件系统。
最微妙的是,我们的代码基本只会用到最上层,不过有些操作会间接导致 Core Data 深入到其他层。
避免获取请求
优化获取请求
插入和修改对象
如何构建高效的数据模型
字符串和文本
独家秘诀的可调参数
总结
与网络服务同步
许多应用程序会和后端同步它们的本地数据,我们想要演示一种针对这类使用场景而设计的有效的通用设置。我们的同步架构的一个主要设计目标是确保清晰的关注点分离 (separation of concerns, SoC),即每个小的部分只承担非常有限的责任。
Moody 示例应用程序使用了这种设置来满足它特定的同步需求。我们希望这些示例代码可以帮助你了解这个同步架构的使用方式。
在本章中,本地 (local) 和远程 (remote) 这些词语具有非常特殊的含义:本地是指在设备上产生的事件,而远程是指在服务器端产生的事件,在我们的例子中,指的是 CloudKit。一个本地更改,也就是指发生在设备上的一个更改,举个例子来说,比如像是创建一个新的 mood 这样的由用户行为所产生的更改。相应地,术语远程标识符 (remote identifier) 指的是 CloudKit 用来标识特定的对象的标识符。在整个代码和本章中,使用本地和远程这些词语可以简化很多术语。
本章不会那么详细地介绍实际示例代码的细节,相反,我们主要会尝试向你展示整体大局:如何组织一个代码库,使得它能够与后端同步本地数据。GitHub 上的 Moody 应用程序有一个相对简单实现的完整代码。如果你读完了这一章,可以参考这个示例项目里更多的细节。
组织和设置
同步架构
上下文属主
响应本地更改
响应远程更改
更改处理器
删除本地对象
分组和保存更改
扩展同步架构
使用多个上下文
在本章中,我们要来学习一些相对复杂的 Core Data 栈设置方式;尤其是探索如何在多线程的环境下正确使用 Core Data。与此同时,因为 Core Data 栈允许多种不同的设置方式,所以我们也要来讨论其中一些设置方式的优缺点。
本书第一部分中,我们使用了最简单的 Core Data 栈 — 一个持久化存储 (NSPersistentStore),一个持久化存储协调器 (NSPersistentStoreCoordinator) 以及一个托管对象上下文 (NSManagedObjectContext) — 构建了一个示例应用。这种设置方式对于大多数存储需求不是很高的应用来说已足够。如果你能够习惯这种用法,那就用它吧,因为这样你就不用花大量的时间去处理并发环境所带来的那些复杂问题了。
在前一个关于同步的章节中,我们使用两个上下文拓展了这个简单的栈,其中一个位于主线程,另一个则位于后台线程。这两个上下文都连接到了同一个持久化存储协调器。这种方式在并发环境下是最简单又最稳定的。它同时也展示了 NSPersistentContainer 的 API 使用起来是有多么的方便。除非有特殊的需求,否则这应该就是使用多个上下文的最好方式。
在本章里,我们会进一步讲解这种设置方式,同时也会探讨其他设置方式的优缺点,从而加深对 Core Data 栈的理解。然后在下一章里我们会讨论在 Core Data 里使用多个上下文的一些陷阱。不过首先让我们回顾一下 Core Data 并发模型的基础知识。
并发的规则
如果你不是很熟悉并发和调度队列 (dispatch queue) 的话,我们建议你在开始阅读本章前能够花一些时间了解一下它们的基本概念。这里有两个很好的资源,一个是 Apple 的并发编程指南,另一个是 objc.io 在 2013 年 7 月发布的一篇关于并发编程的博客。
Core Data 有一个简单直接的并发模型:上下文以及它的托管对象必须而且只能够在它所处的队列中被访问。而其他处于上下文下面的那些组件 — 比如,持久化存储协调器,持久化存储,以及 SQLite — 是线程安全的并且可以在多个上下文之间共享。
当你创建一个托管对象上下文实例的时候,会在构造方法 init(concurrencyType:) 里指定并发类型。当你创建一个托管对象上下文实例的时候,会在构造方法 init(concurrencyType:) 里指定并发类型。不过当你使用 NSPersistentContainer 来设置你的 Core Data 栈的时候,它会自动帮你指定并发的类型。
在本书第一部分里,当使用容器 (NSPersistentContainer) 的 viewContext 时,我们使用的是第一种并发类型:.MainQueueConcurrencyType,这种类型会将上下文绑定到主线程上。第二种类型:.PrivateQueueConcurrencyType,会将上下文绑定到一个由 Core Data 自行管理的后台线程上。比如当你在 NSPersistentContainer 对象上调用 newBackgroundContext 或 performBackgroundTask 时返回的上下文就是这种类型。
如果你问本章最重要的一个知识点是什么,那就是,在访问上下文和它的托管对象之前,一定要调用 performBlock(_:) 把任务调度到上下文所处的队列上执行。这是避免并发所带来的问题的最有效方法。
当开始使用多个上下文后,你肯定会遇到需要合并不同上下文中的数据更改的时候。你可以通过以下步骤将这些更改合并:首先注册观察某个“上下文已保存”通知 (NSManagedObjectContextDidSaveNotification)(详情可参考更改和保存数据的章节),然后调度到另一个上下文所处的队列,最后调用 mergeChangesFromContextDidSaveNotification(_:) 方法,它会将通知所携带的 userInfo 字典里的更改进行合并:
let nc = NotificationCenter.default
token = nc.addObserver(
forName: .NSManagedObjectContextDidSave,
object: sourceContext, queue: nil) { note in
targetContext.perform {
targetContext.mergeChanges(fromContextDidSave: note)
}
}
将一个“上下文已保存”通知合并到另一个上下文后,会在这个上下文中刷新被更改的对象,移除被删掉的对象,并将刚被插入的对象进行惰值化 (fault) 处理。然后这个上下文会发送一个对象已变更的通知,其中包含了位于这个上下文中的对象的所有更改:
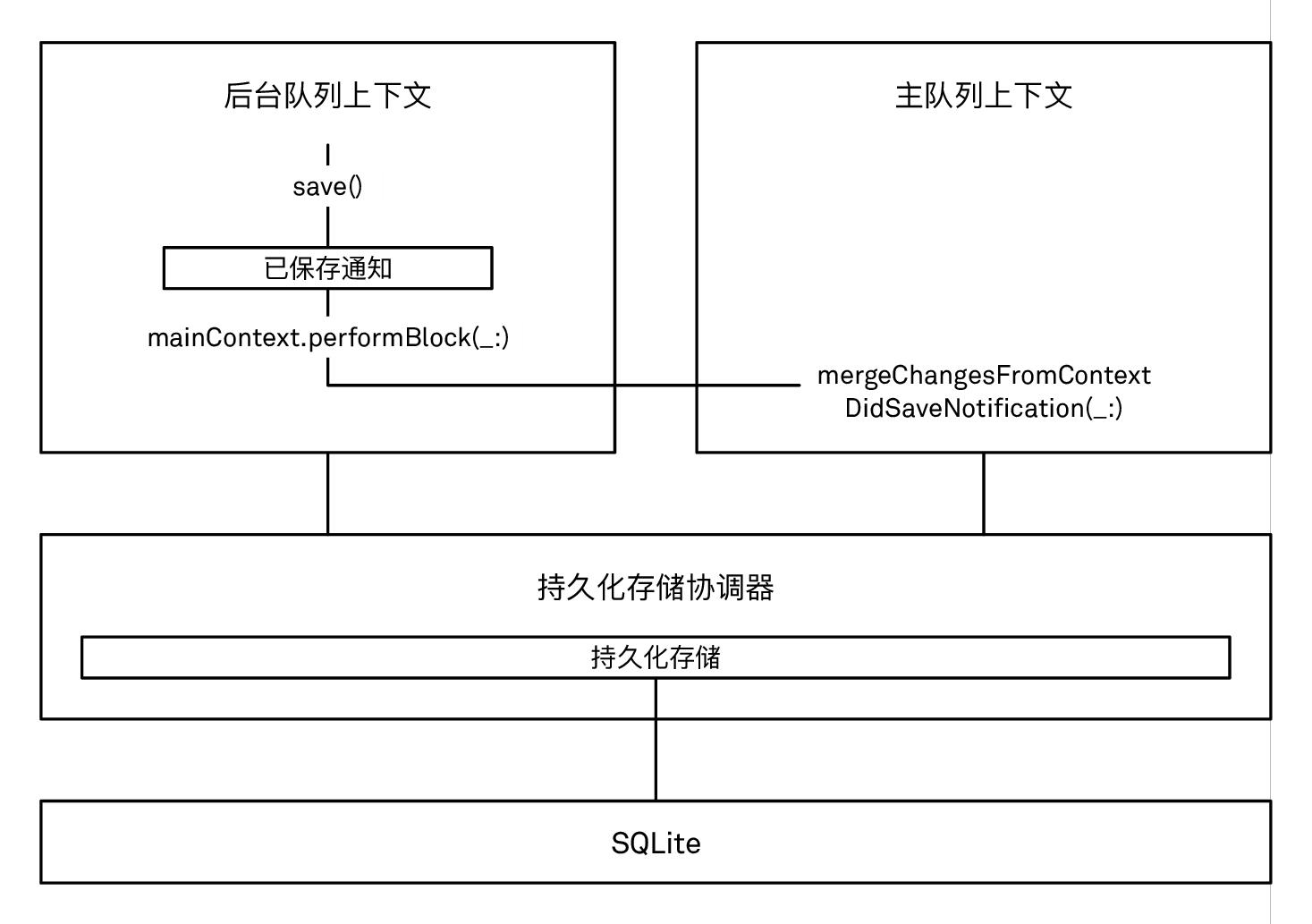
通过合并上下文已保存通知来协调不同上下文之间的更改
这就是本章第二个重要的知识点,它同样能让你避免并发所带来的问题:不同上下文中的操作必须完全分离,上下文之间的数据交换只能通过“上下文已保存”通知进行,切记不要在不同上下文之间随意调度。
这个知识点看起来有些过于绝对,毕竟在某些用例中,我们可能需要在不同的上下文之间传递对象,比如在后台线程执行复杂的搜索。这确实是一个很好的用例,不过其他的那些用例应该都是些罕见的例外。我们的示例应用的数据同步部分正是如第二个知识点所描述的那样工作:所有的数据同步代码只在它所处的上下文中执行,这个上下文和 UI 线程所使用的上下文完全分离,不同上下文之间的合并也只通过“上下文已保存”通知进行。
在不同的上下文之间传递对象
除了合并“上下文已保存”通知这个方式外,如果你需要使用另一种方法来在不同的上下文之间传递对象,就必须使用一种间接的方式:首先调用 perfomr 方法将对象的 ID 传递到另一个上下文的队列上,然后调用 object(with objectID:) 方法重新实例化这个对象。比如像这样:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
let ids = objects.map { $0.objectID }
mainContext.perform {
let results = ids.map(mainContext.object(with:))
//... results 现在可以在主队列中使用了
}
}
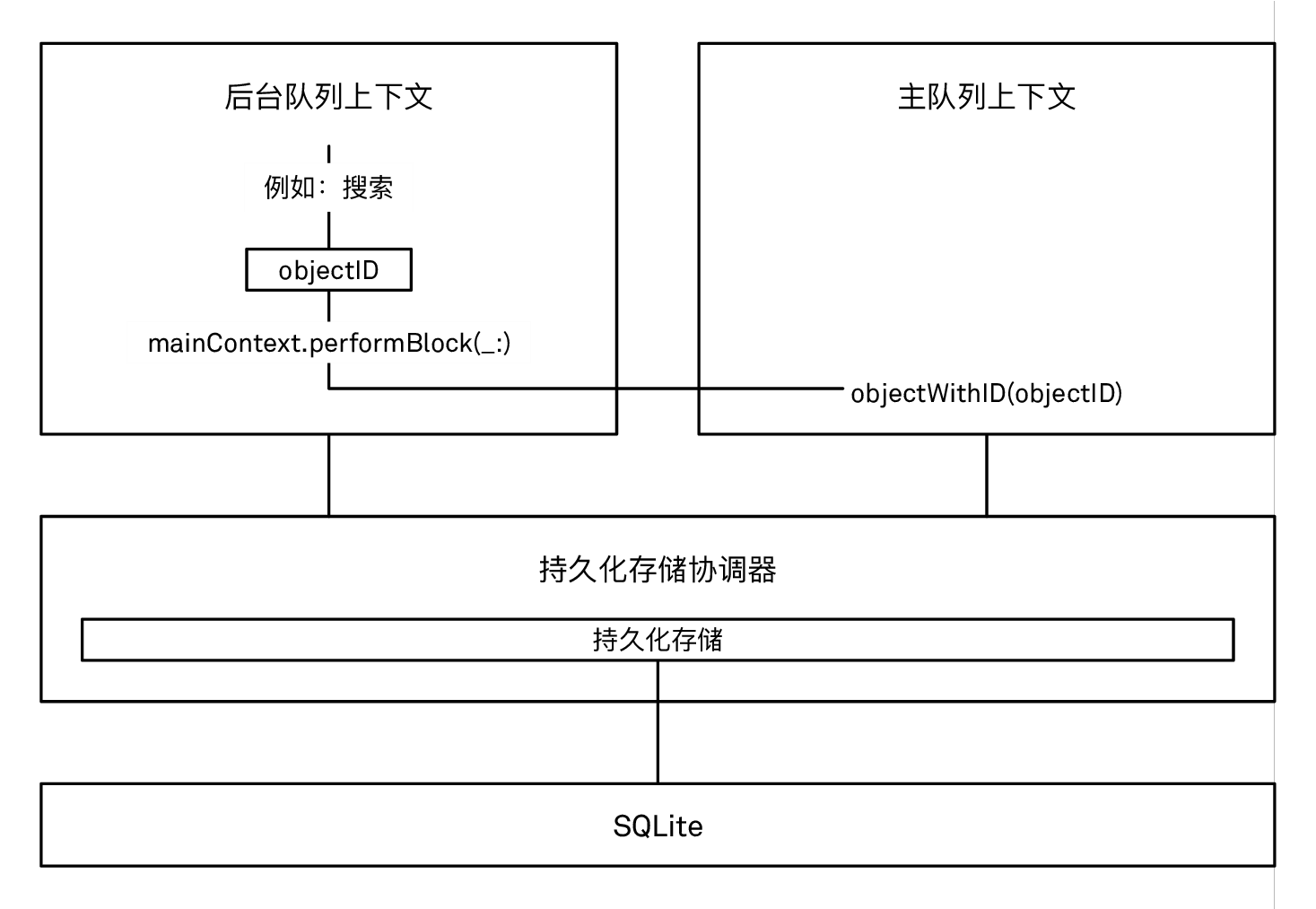
通过将对象 ID 从一个上下文传递到另一个上下文来处理托管对象
你只能将对象的 ID 传递到另一个上下文中并且重新实例化该对象,这个做法从技术上来讲完全正确。不过我们还有另一个方法,它能够保证对象的行缓存条目一直有效。这个特性非常有用,因为比起直接从 SQLite 中获取那些对象的惰值,从行缓存中获取它们可以使目标上下文更快地进行数据填充。
具体做法是,将对象直接传递到目标上下文中,然后在该上下文所处的队列中获取对象的 ID。但是有一点必须严格遵守,除了获取对象的 ID,绝对不要对它做其他任何操作,具体代码如下:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
mainContext.perform {
let results = objects.map { mainContext.object(with: $0.objectID) }
// ... results 现在可以在主队列中使用了
}
}
如果对象 ID 所处的上下文连接到的是另一个持久化存储协调器,那么在当前上下文中,你必须通过该对象的 URIRepresentation 来重建对象的 ID。可以使用持久化存储协调器的 managedObjectID(forURIRepresentation:) 方法来实现这个操作:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
let ids = objects.map { $0.objectID }
separatePSCContext.perform {
let results = ids.map {
(sourceID: NSManagedObjectID) -> NSManagedObject in
let uri = sourceID.uriRepresentation()
let psc = separatePSCContext.persistentStoreCoordinator!
let targetID = psc.managedObjectID(forURIRepresentation: uri)!
return separatePSCContext.object(with: targetID)
}
// ... results 现在可以在主队列中使用了
}
}
(为了简短起见,在上面的代码片段中我们使用了强制解包来获取可选值。当你在实际使用时,务必使用 guard 关键字来获取这些值。) 注意在这种情况下,我们并不需要像之前的方法那样在 perform 中保留对象的引用来保证行缓存条目有效,因为两个上下文并没有共享同个协调器,所以它们无法共享行缓存。
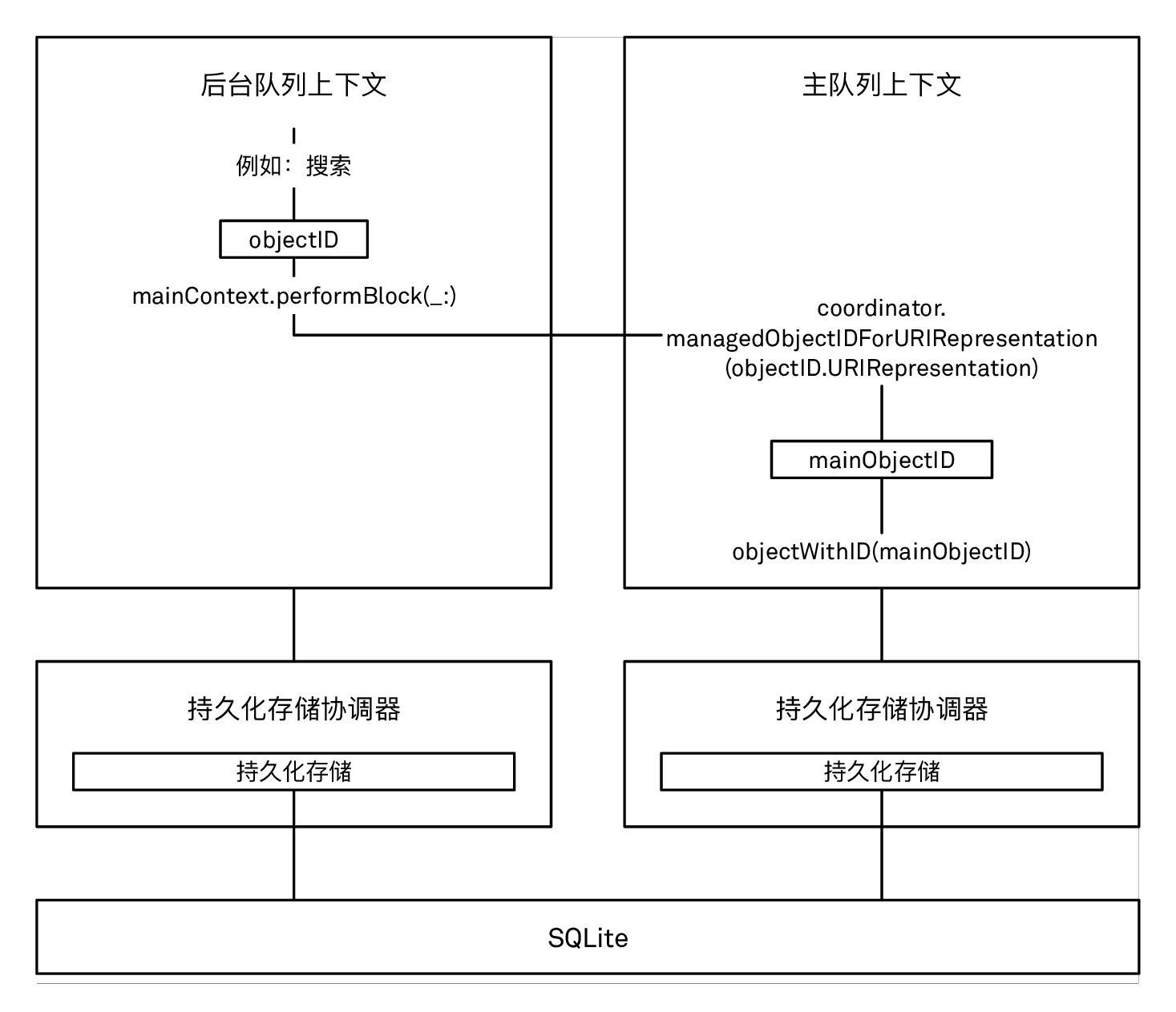
在两个连接到不同的持久化存储协调器的上下文中处理托管对象
上面所介绍的就是在 Core Data 中使用多个上下文的一些基本方法。这些方法实际使用起来其实并不复杂,只要你能够严格遵守以下规则:不同上下文中的操作必须完全分离,进行任何操作前必须调度到上下文所处的队列中,在不同的上下文之间只能传递对象的 ID。
除了这些基本规则外,在并发环境下使用多个上下文不可避免地会带来一些复杂的问题 —— 比如冲突以及竞争条件。在下一章里,我们会详解如何处理这些问题。
我们在前面简单介绍了如何在不同上下文之间合并更改。在开始介绍 Core Data 不同栈设置方式的优缺点之前,我们要来深入讲解一下这个知识点。
合并更改
将更改从一个上下文合并到另一个 (或多个) 上下文中的方法非常直截了当:首先添加一个观察者来监听 Core Data 所发送的上下文“已保存通知”。在观察者接到该通知后,再调用 perform 方法调度到目标上下文队列中。最后在该队列中,将通知作为参数传递给 mergeChanges(fromContextDidSave:) 这个方法。
在合并过程中,Core Data 会从通知所携带的托管对象中提取出对象的 ID。Core Data 并不能使用这些对象本身,因为它们只能在所处的上下文的队列中才能被访问。当目标上下文获取了这些对象的 ID 后,它会按照下面的方式处理对象的更改:
新插入的对象在目标上下文中会以惰值的形式存在。
注意如果没有强引用指向被插入的对象,那么这些惰值在合并后就会被释放。在你监听“对象更改”通知的时候,你会有机会强引用到这些对象。
至于更新了数据的对象,只有那些在目标上下文中注册过的才会被刷新,其他的都会被忽略掉。
如果在目标上下文中,这些对象的数据也被更改了,那么这些更改会逐一合并到对象相应的属性上,如果出现冲突,那么会以目标上下文中的更改为最终结果。
删除的对象也一样,只有那些在目标上下文中注册过的才会被删除,其他的都会被忽略。
如果删除的对象在目标上下文中被更改了,这些更改会被无视,因为对象会被直接删掉。所以如果你正在使用这些对象,那么此时你必须做出适当的应对,就如同我们在第一章中关于托管对象更改通知观察者所做的那样。
在更改和保存数据一章里我们提到过,当合并完成后,processPendingChanges 方法会被调用,同时发送一个“对象已更改”通知。(针对一个合并操作,Core Data 可能会发送多个对象已更改通知,所以你不能假设一个合并操作只会发送一个通知。) 通过观察这个通知,你就有机会对这些合并的更改做出应对。要记住的是,位于“上下文已保存”通知中的更改 (比如更新那些并没有在目标上下文中注册的对象),如果没有影响到目标上下文的话,那么这些改动就不会出现在“对象已更改”通知中。
要注意的是,因为我们在 perform 中进行合并更改操作,所以它是异步的。而 Core Data 的上下文已保存通知是同步发出的,这就会导致观察这个通知的那部分代码会在 save 方法返回前被执行。也就是说在完成保存操作以及在另一个队列上下文中完成合并更改操作之间会有一定的时间差。我们会在下一章的在并发环境下进行删除操作这部分里来讨论这个问题。
当把一个“上下文已保存”通知从一个上下文传递到另一个的时候,只要使用我们之前所讲的关于在上下文之间传递对象的方法,就能够保证对象的行缓存条目一直有效:通知会强引用源上下文以及所有需要保存的对象。由于我们在 perform 闭包内部使用了通知对象,这个通知本身也会被强引用。因此,当合并时,所涉及到的对象会一直有效,这也保证了它们的行缓存条目也同时有效,就如我们在访问数据章节所提到的那样。这是一个非常重要的细节,因为之后当那些被合并操作所插入的惰值需要被访问时,Core Data 就不用反复从 SQLite 中获取这些值,从而节省不少时间。
默认的并发设置
嵌套上下文的设置
嵌套上下文的复杂性
总结
使用多个上下文的问题
当你开始同时使用多个托管对象上下文时,在这些上下文里更改数据就可能会出现冲突。
在第二章里,我们提到了保存时发生冲突以及 Core Data 如何通过两步乐观锁 (optimistic locking) 来检测这些冲突。在本章中,我们会进一步讲解如何使用那些预定义的合并策略来解决这些冲突,以及如何自定义一个合并策略。
我们也会讨论如何将托管对象上下文钉扎到数据库的某个特定状态,以及如何避免在删除对象时可能发生的竞争条件,还有如何在多个托管对象上下文中确保唯一性要求。
保存冲突及合并策略
查询世代
删除对象
唯一性约束
总结
谓词
一个谓词封装了一种标准,对象要么符合这个标准,要么不符合。比如这样的一个问题或者说是标准 - “这个人的年龄是否超过了 32 岁?”就可以被封装成一个谓词。然后我们就可以用这个谓词来判断某个人 (Person) 对象是否符合这个标准。
NSPredicate 的核心是 evaluate(with:) 方法,这个方法需要一个对象作为参数然后会返回一个布尔值。谓词在 Core Data 中扮演了一个非常特殊的角色。Core Data 会将谓词转换成一个 SQL WHERE 语句,然后就可以通过 SQLite 来迅速地在数据库中的对象上执行谓词,而不用在内存中创建那些对象。
我们使用谓词来匹配某个特定的对象,或者从一个对象集中筛选出一个更小的集合。无论如何,值得注意的是我们既可以将谓词作为获取请求的一部分来使用,也可以直接使用谓词的 evaluate(with:) 方法来筛选对象。
在本章中,我们不光会介绍那些简单的谓词,也会介绍一些更复杂的例子。本章的讨论侧重于 Core Data 中谓词的使用。当然谓词也可以被独立地使用,不过我们不会在这里讨论更多的细节。
你可以在 GitHub 上找到这个与本章内容有关的 playground。
简单谓词
用代码来创建谓词
格式字符串
合并多个谓词
遍历关系
匹配对象和对象 ID
匹配字符串
可转换的值
性能和排序表达式
总结
文本
在 Core Data 中存储字符串是直截了当的。但是从另一方面来说,字符串的搜索和排序却是非常复杂的。由于 Unicode 和自然语言的复杂性,所以两个字符串相等并不一定意味着它们所对应的字节也相等。同样的,要搞清楚两个字符串中哪个字符串排在前面也是个很复杂的问题;这很大程度上取决于当前的语言区域 (locale)。
Unicode 的复杂性
处理文本是很困难的,这一章并不会广泛地讨论 Unicode 方面的内容。对于 Unicode,有很多不错的资源值得你去阅读和学习。我们推荐你从 objc.io 上的这篇讲 Unicode 的文章开始,同时 Unicode 协会的主页也是个很好的资源,在那里你能了解更多 Unicode 的那些错综复杂的细节。但是,在本章中,我们只会通过几个例子来简单地说明 Unicode 方面的内容。
我们假设在 City 这个实体上有个属性叫 name,并且在我们的应用中,用户可以通过名字来搜索一个城市。
法国的第 14 大城市叫 Saint-Étienne。当用户在搜索框中输入 Saint-Étienne 时,我们希望使用搜索谓词来匹配这个城市。但是有一个问题,字母 É 在 Unicode 中有两种表示方式:一种是由单个 Unicode U+00C9 (E 带个重音符号) 来表示,另一种是由 U+0301 和 U+0045 这两个 Unicode 组成 (前者是一个重音符号,后者是英文字母 E)。从用户的角度来说,这两个表示是一模一样的。另外,用户可能希望即使输入的城市名是小写的,也还是能正确搜索到这个城市。甚至即使搜索 Saint Etienne 这个字符串也还是能正确匹配到这个城市。但是问题就是,这些字符串所对应的字节是完全不同的。虽然用户可能会觉得它们是相同的,但是如果只是进行简单的比较,那么这几个字符串是不可能相同的。
在某些语言区域设置下,当在搜索框中输入 Århus 时,用户希望能够搜索到 Aarhus 这个丹麦城市。Å 这个字母既可以用 U+00C5 (A 字母上面加一个圆圈) 这个 Unicode 表示,也可以通过 U+030A (字母上面的圆圈) 和 U+0041 (字母 A) 组合起来表示。同时,在非拉丁语的文字中,我们要确认下是否需要匹配那些相应的拉丁文字。比如用户是否能够通过输入 “Xi'an” 来匹配作为中文字符串存储的中国城市“西安”?这里的 ' (U+0027) 应当如何处理?还有当用户输入 ’ (U+2019) 时是否能够等效于这个 ' (U+0027) 符号?
这些问题的答案与使用的领域是高度相关的。想要解决所有这些问题是非常复杂的,所以我们必须要根据手头上的具体问题来确定到底哪个需要解决,哪个不需要解决。可能对于我们的应用来说需要让 saint-etienne 能够匹配 Saint-Étienne,但是 Århus 是否能够匹配 Aarhus 就完全不重要。
当排序的时候也会发生类似的问题。哪怕只是拉丁语文字,事情也要比乍看之下更复杂。当我们把字母单独拿出来时,很明显 B 要排在 A 之后。但是如果是一个完整的单词那情况可能就不一样了。排序的顺序取决于用户的区域设置,也就是用户的操作系统所设置的语言。
仅仅在德国,ö 这个字母就有两种排序顺序:它既等于 o 也等于 oe。所以在德语中,Köln 会排在 Kyllburg 前面 (因为 o 排在 y 前面)。但是在瑞典语中,字母 ö 排在所有其他英文字母之后,所以 Sundsvall 排在 Södertälje 之前。
一个丹麦的用户会认为 Viborg,Ølstykke-Stenløse 和 Aarhus 这三个城市的排序顺序是正确的。这是因为字母 Ø 排在字母 Z 之后,然后两个 A 在一起从语义上来讲等价于字母 Å,这个字母在丹麦语字母表中排在最后。
当不同字母混合起来时,Москва 这个单词是应该排在所有字母都是拉丁文的单词之前呢还是之后?或者是混合到拉丁文单词之中,比如 Москва 排在 Madrid 之后?
对于这几个问题还是同样的答案,一切取决于应用域,也就是你的应用需要解决怎样的问题。
在编程时同样需要特别注意的是,在某些情况下我们所使用的字符串并不是用户可见的。如果某个字符串是一个用户不可见的标识符或者键,那么我们可能就不希望 art 能够匹配 Art。
搜索
排序
总结
数据模型版本以及迁移数据
在关系这一章里我们已经提到过,当通过一个数据模型打开 SQLite 存储文件时,如果这个数据模型无法匹配数据库中的数据,那么就会导致程序崩溃。因此我们引入了数据模型版本和数据迁移这两个概念。随着应用的不断更新以及新功能的添加,数据模型必须适应那些新的需求,比如添加新的属性等。我们不能直接在当前数据模型上做更改,而是必须创建新的数据模型版本,然后将现有的数据从旧的数据模型迁移到新的数据模型上。在这一章里,我们会来讲解更改数据模型版本和数据迁移具体是如何运作的。
我们在 GitHub 上为这一章创建了一个独立的示例项目,其中我们在 Moody 这个数据模型上进行了一系列的数据迁移,以此来展示不同的数据迁移技术。这个项目包含了一个测试 target,它会将迁移结果和硬编码的测试用例进行比较,从而来测试那些对预先填充好的数据进行迁移时的正确性。我们会在后面进一步介绍如何建立这些测试。
在深入数据迁移这个话题之前,我们建议你仔细考虑下是否真的需要进行数据迁移操作。因为数据迁移不仅会给你的应用添加额外的复杂性,还会给你带来更多的维护工作。举个你不需要做数据迁移的例子,如果你仅仅使用 Core Data 来做为服务器端数据的本地离线缓存的话,那么你可以直接删除本地数据,然后创建一个全新的持久化存储,再从服务器上获取你需要的数据并将它们存入这个新建的持久化存储。很显然在很多情况下你确实需要做数据迁移,但是在你做决定之前我们还是建议你先思考下是否真的需要做数据迁移。
数据模型版本
数据迁移的过程
推断的映射模型
自定义映射模型
数据迁移和用户界面
测试数据迁移
总结
性能分析
我们已经在关于性能的章节中从多方面讨论了如何在使用 Core Data 时保证高性能。在本章中,我们会专注于如何通过性能分析 (profiling) 来确定 Core Data 的性能瓶颈在哪里,以及如何使用这些信息来改进你的代码。
本章中展示的这些技术不光能用来有效地分析你的应用,它们也可以帮助你更好地理解 Core Data 栈中具体发生了什么。比如说,在本书的创作过程中,我们就大量地使用了下面提到的这个 Core Data 的 SQL 调试输出工具。
SQL 调试输出
Core Data Instruments
线程保护
总结
关系型数据库基础和 SQL
Core Data 的默认存储是 SQLite 数据库。Core Data 中绝大部分概念是围绕 SQLite 数据库来设计的,我们会在本章里更进一步来讲解这些概念。这些内容并不是你开始使用 Core Data 的先决条件,但是尝试理解 Core Data 的内部机制会帮助你更好地使用它。
不过在这里先要提出一个警示:这一章会跳过一些细节,而且我们会从数据库在 Core Data 中的使用方式这个角度出发来讲解关系型数据库,本章的重点就在于帮助你理解这个知识点。因此,我们不会详解创建数据表和插入数据方面的知识。虽然它们看起来很基础,但是对于我们本章的目的来说它们完全不重要。